Statements Best Describes a Web Crawler
A web crawler is a program that browses the World Wide Web in a methodical fashion for the purpose of collecting information. A web crawler should be able to connect with Google Analytics with ease.

Efficiently Harvesting Deep Web Interfaces Based On Adaptive Learning Using Two Phase Data Crawler Framework Springerlink
Hits Readers develop and refine news reports by commenting on them and posting contributions.
. We then discuss current methods to evaluate and compare performance of difierent crawlers. The main purpose of this bot is to learn about the different web pages on the internet. Each crawler thread fetches a document from the Web.
Select all the correct options. Either an editorial message or a commercial message. Each crawler thread removes the next URL in the queue.
An editorial message only. The Library archives websites that are selected by the Librarys subject experts known as Recommending Officers based on guidance set forth in Collection Policy Statements and Supplemental Guidelines for Web ArchivingCollecting occurs around subjects themes and events identified. Or to check if a URL already.
Searches the Web or only images video and news. Origin of the question is Problem Solving topic in section Problem Solving of Artificial Intelligence. It supports Javascript pages and has a distributed architecture.
This is really all the difficult code. InfoSpace product offering combined results from Google Yahoo Bing and Ask. It must detect mobile elements.
When the document is not in HTML format the crawler converts the document into HTML before caching. C Simple reflex agent. It should find broken pages and links with ease.
A Web crawler sometimes called a spider or spiderbot and often shortened to crawler is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing. A web crawler must support multiple devices. What are the requirements for synchronization between these concurrent activities.
What are the different types of cybersecurity threats. PySpider is a Powerful Spider Web Crawler System in Python. An event or act that could cause the loss of IT assets.
I have added Tika as a reference to my StormCrawler implementation and that enables to fetch the PDF documents in the crawl. It should support multiple file formats. The web crawler is an example of Intelligent agents which is responsible for collecting resources from the Web such as HTML documents images text files etc.
Web crawlers are used for a variety of purposes. A Web crawler an indexer a database and a query processor are all components of this. It presents a view of long-term technology integration.
I got this question in my homework. Web Crawler is a bot that downloads the content from the internet and indexes it. Search engine A search engine returns a list of these which are links to Web pages that match your search criteria.
We list the desiderata for web crawlers in two categories. It presents a view of short-term technology integration. This describes the basic concepts in Web crawling.
Most prominently they are one of the main components of web search engines systems that assemble a corpus of web pages index themandallowuserstoissuequeriesagainsttheindexandfindtheweb. Web search engines and some other websites use Web crawling or spidering software to update their web content or indices of other sites. As the name suggests the web crawler is a computer program or automated script that crawls through the World Wide Web in a predefined and methodical manner to collect data.
You can use RabbitMQ Beanstalk and Redis as message queues. 2 Building a Crawling Infrastructure. Finally we outline the use of Web crawlers in some applications.
Web Crawler is aan ____________. Features that web crawlers must provide followed by features they should provide. It provides immediate communication to and receives feedback from customers.
Identify a true statement about the function of Googles Ad Words. Which statement best describes white light after it passes through a prism. Also offers white pages and yellow pages.
After you finish this book you should have a working web crawler that you can use on your own website. The Web contains servers that createspidertraps which aregen-erators of web pages that mislead crawlers into getting stuck fetching an infinite number of pages in a particular domain. The page is usually an HTML file containing text and hypertext links.
Web 20 communication tools are primarily passive and static. Following this we review a number of crawling algorithms that are suggested in the literature. Select the correct answer from above options.
36 The main function of problem-solving agent is to________. It must identify redirect issues and HTTP HTTPS issues. Frequently Asked Questions How does the Library select websites to archive.
This kind of bots is mostly operated by search engines. PySpider can store the data on a backend of your choosing database such as MySQL MongoDB Redis SQLite Elasticsearch Etc. The negative consequences or impact of losing IT assets.
Solution All you have to do is provide a URL and our Web Crawler will access it and automatically fetch all the hyperlinks visit each one and retrieve the page load time and a screenshot for each one. A cybersecurity exploit is ______. A web crawler must detect robottxt file and sitemap easily.
A commercial message only. But the Title Authors and other properties dont get parsed. The Industrial Age is an era in which people engage in networked communication collaborate across boundaries and solve problems communally.
The web crawler tool pulls together details about each page. A condition that could cause the loss of IT assets. Web crawler social bookmarking urban legend dynamic URL power power If you hear the phrase And now a word from our sponsors you are about to hear.
A search engine is a web server that responds to client requests to search in its stored indexes and concurrently runs several web crawler tasks to build and update the indexes. D Model based agent. Titles images keywords other linked pages etc.
A Intelligent goal-based agent. There is even a section on the page that describes how to get all the links from a webpage. Web Crawler Introduction The Start Web Crawler action allows you to check all the pages from your web application.
It redirects Web pages to different sites if the link fails. The crawler initiates multiple crawling threads. BIS 3233 Cybersecurity study questions.
You can then append all the links you got to a list go through each link repeat the same process as above and then add the resulting links to the list again and recursively repeat this process for however long. I have tried with different combinations to indexmdmapping and added the corresponding properties to ES_IndexInit but the content field in Kibana index for PDFs. For example to cache web pages we need some thing like FILESTREAM of sql server.
Neither an editorial message nor a commercial message. A web crawler also known as a robot or a spider is a system for the bulk downloading of web pages. My experience says that a web crawler has many parts and services and each part need some specific features.
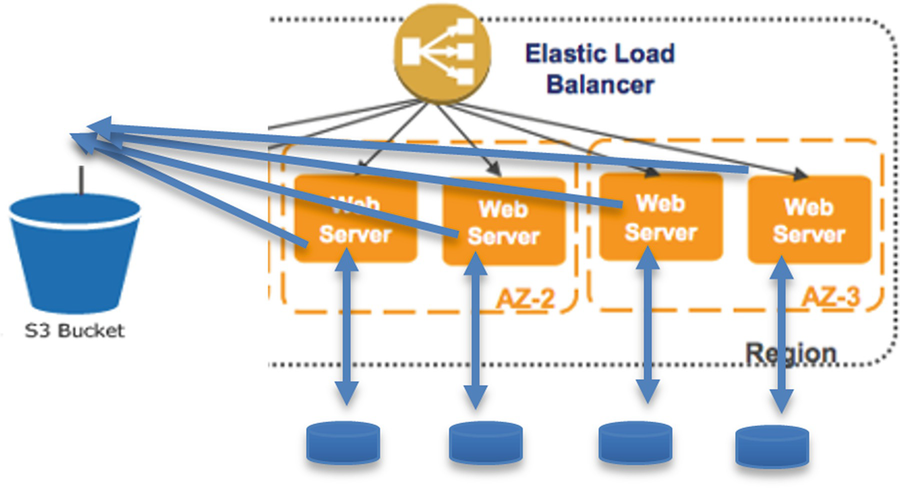
A Quick Test Of Your Cloud Fundamentals Grasp Springerlink
Efficiently Harvesting Deep Web Interfaces Based On Adaptive Learning Using Two Phase Data Crawler Framework Springerlink
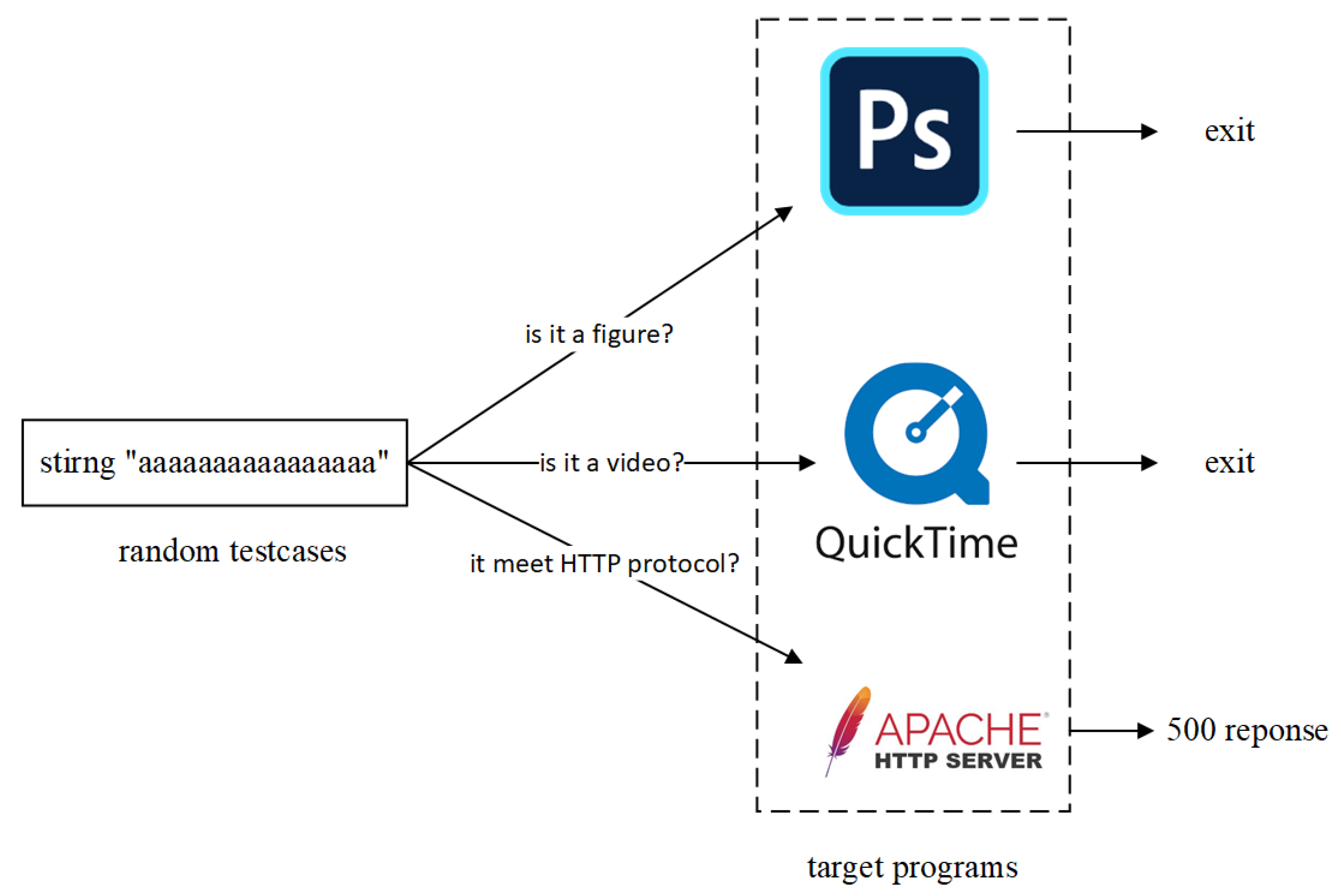
Electronics Free Full Text Cefuzz An Directed Fuzzing Framework For Php Rce Vulnerability Html
No comments for "Statements Best Describes a Web Crawler"
Post a Comment